出掛けるときの持ち物リスト
共通
- スマホ
- スマートウォッチ
- 携帯
- 財布
- タバコ
- iQOS
- サイドバッグ
サイドバッグ
- モバイルバッテリー
- USBケーブル
- USB充電器
- ワイヤレスイヤホン
- イヤホン
- 腕時計
- 薬
- 筆記用具
- 嗅ぎ煙草
泊まり
- 着替え
- 下着
- 靴下
- 寝間着
- PC
- 会社PC
- 長めのUSB充電ケーブル
- 予備メガネ
- メガネケース
- 予備スマホ
- 折りたたみ傘
- テーブルタップ
- ビニール袋
- タオル
- 電気シェーバー
- 歯ブラシ
- カメラ
- DDNSが動くことを確認
- 電気ケトルの水を捨てる
キューブの大会
- 競技種目のパズル
- パズルの予備
- 次の大会のパズル
- 会場で誰かに教わる用
- 潤滑剤
- ドライバー、調整器具
- アイマスク
- イヤーマフ
- 名札入れ
- タイマー
- ストップウォッチ
- アクションカメラ
- バッテリー
- カメラ
- カイロ
- 爪を切る
- 大会前のMy Resultsのスクショを撮っておく
- スマホの目覚ましを切る
会社
- 会社PC
- 社員証
メガミンクスで3分30秒を目指す解法

3x3x3キューブをCFOPで解ける人向け。
私は別にメガミンクスが速くはない。 だからこそ、遅い仲間が増えてほしいという気持ちで書いている(下衆)。 でもこの解法自体は速くなる道の上には乗っていると思う。
Kanto Autumn PM 2025
Kanto Autumn PM 2025 | World Cube Association
3x3x3とメガミンクスの大会。 2025年9月21現在、まだだいぶ空きがある。
で、この大会はメガミンクスの制限時間がとても緩い。 カットオフ(切らないと平均の記録が残らない)が3分30秒、制限時間(切らないと単発の記録も残らない)が4分。
5月の大会はカットオフが1分30秒の制限時間が2分だった。 制限時間はギリギリクリアできたものの、カットオフは全然無理だった。 私が遅いだけかと思ったけど、話を聞くにこのカットオフはけっこう厳しいらしい。
3分30秒なら、(3x3x3で知っているであろう以外の)手順を覚える必要も無く、他の種目に慣れている人だと1日練習すれば達成できるのではないだろうか。
「やっぱり3分30秒だと大会運営の時間的に厳しいね」となって1分30秒に戻るかもしれないし、平均の記録を手に入れるなら今がチャンス。
Kansai Mega Day 2025 | World Cube Association
11月の大阪もまだ空きがある。
スクランブル
スクランブルできないと練習もできない。
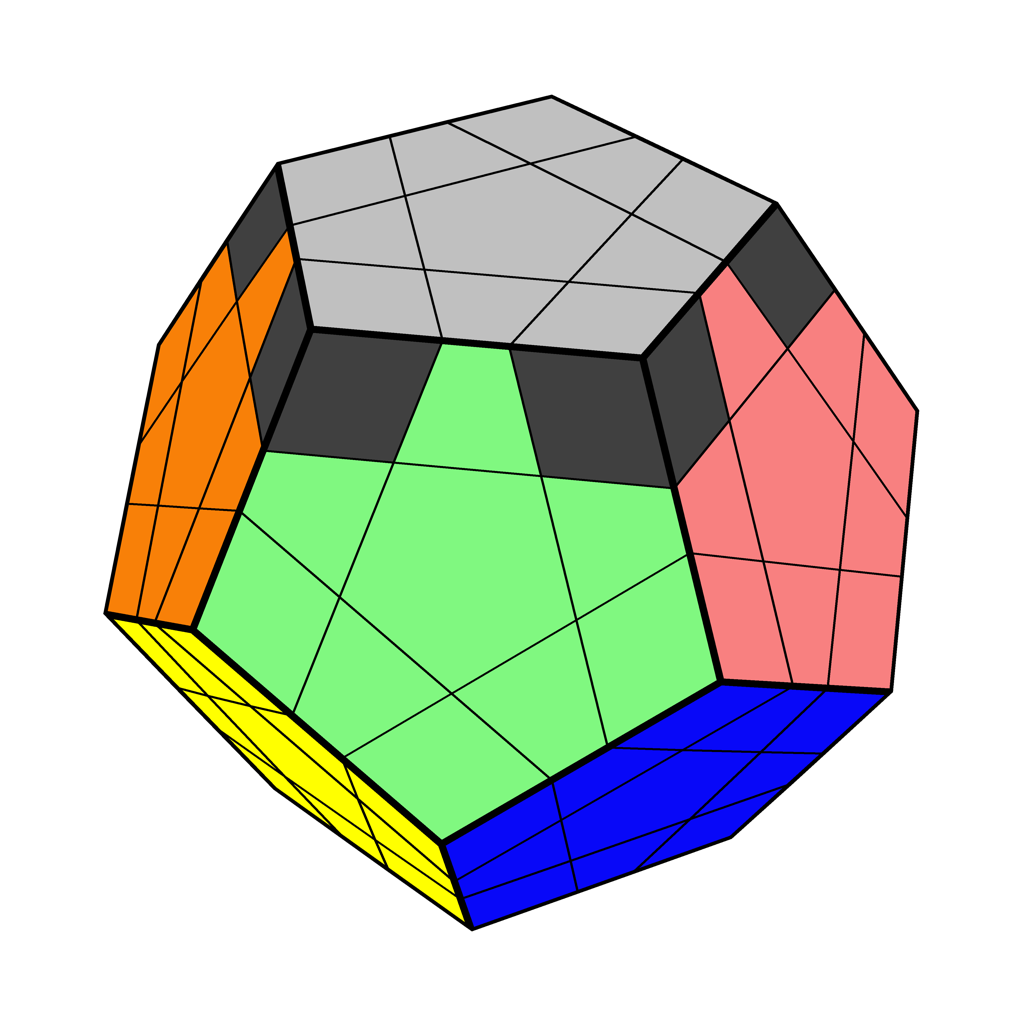
メガミンクスはスクランブルの方法が特殊。 スクランブルはこんな感じ。
R-- D-- R++ D++ R-- D-- R-- D-- R-- D-- U' R++ D-- R++ D-- R++ D-- R++ D-- R-- D-- U' R-- D++ R++ D-- R-- D-- R++ D++ R-- D-- U' R++ D++ R++ D++ R-- D-- R-- D-- R-- D++ U R++ D-- R++ D++ R-- D-- R++ D++ R++ D++ U R-- D-- R-- D++ R++ D++ R-- D++ R-- D-- U' R++ D-- R++ D-- R++ D++ R++ D++ R++ D++ U

白面を上、緑面を手前に持つ。 R は上の図の左の赤い部分を、 R++ なら時計回りに、 R-- なら反時計回りに2/5回転多層回しする。 D は上の図の中央の赤い部分を、 D++ なら時計回りに、 D-- なら反時計回りに2/5回転多層回しする。 これらは左手で灰色の部分を持って回すと良い。 U は上の図の右の赤い部分を回す。 U については、 U なら時計回り、 U' なら反時計回りに1/5回転。 2/5回転ではない。

上のスクランブルでこの図のようになれば正しくスクランブルができている。
このスクランブルは、Pochmannさんが考えたらしい。 3x3x3目隠しのM2/OPのOPは、Old Pochmann法の略。 このPochmannさん。
このスクランブル法は、 R と D 、 U の位置は固定で、方向のみが変わっている。
全部で77手あるけれど、 U の向きは直前の D に応じて決まっている。
つまり、このスクランブル法は高々 通りの状態を作る。
ところで、メガミンクスの状態は
通りある。
メガミンクスのスクランブルは、全ての状態の極一部からしか選ばれない。 これが許されているというのはわりと驚き。
メガのスクランブルは実は全パターン出来ない問題 pic.twitter.com/LZVrBirHPm
— ナナシ⚓️ラノベ (@majomajoEnvy) 2025年5月8日
D--の後には必ずU’が来て、D++の後には必ずUがくるので、70通りです
— ナナシ⚓️ラノベ (@majomajoEnvy) 2025年5月8日
大会規則には
4b3e) 5x5x5 Cube, 6x6x6 Cube, 7x7x7 Cube, and Megaminx: sufficiently many random moves (instead of random state), at least 2 moves to solve.
https://www.worldcubeassociation.org/regulations/#4b3e
と書かれている。 全ての状態を生成しないのに「sufficiently many」なのだろうか。 誰かこのスクランブルの性質を解明して、このスクランブルなら通用する解法を編みだしてほしい。 スクランブルが面倒になって恨まれそうw
回転記号
スクランブルは上記の通りであり、WCAの大会規則はスクランブルで使う回転記号しか定義しておらず、公式の回転記号が無い。
この記事では次の回転記号を使うことにする。 Twizzle Editor ᴬᴸᴾᴴᴬ がこの記法だった。

解法の流れ
- スター
- F2L
- S2L
- OLL(エッジ)
- OLL(コーナー)
- PLL(エッジ)
- PLL(コーナー)
OLLとPLLは、エッジとコーナーに分ける。
スター

黒は揃っていないピースを表す。
ある面のエッジを揃える。 3x3x3キューブは十字なので「クロス」だが、メガミンクスは星なので「スター」。
特に手順などは無い。 1個のエッジを揃えるごとにスター面の向きを揃えるのは無駄なので、側面の色の位置関係を把握して、スター面の向き合わせは最後だけにできると良いだろう。
メガミンクスは色が多すぎるので、スター面は固定にするのが良いとされている。
まあ、良いと言われているだけで、本当に固定が速いのかは分からない。 CNの前段階としてデュアルにするとき、3x3x3では白と黄色にするが、メガミンクスでは白と側面の色にするという手があるらしい。
F2L

入れたいスロットの上の面にエッジとコーナーを持ってきて、3x3x3のF2Lと同様に揃えることができる。 正6面体でも正12面体でも1個のコーナーに3個の面が集まっているということは同じ。 例えば、下の図の状態なら R U' R' とか。

エッジとコーナーを持ってくるときに、揃えやすいように考えて持ってくることができると良い……という話がこの動画でされている。
今日のメガの動画
— 佐村健人 (@KuSupermrm) 2025年3月5日
結構話したいことを話せた pic.twitter.com/OTBh0pTGaK
この動画に出てくる「正中線型」が有用。

ここから、 R BR U2 R' でスロットインできる。 エッジの見えている色が赤ならば、 F' L' U2' F 。 S2Lでこの手順を使っていて、BR面がすでに揃っているならば、 R' の前に BR' が必要。
S2L

Second 2 layers。 LL以外を揃える。
一部が揃っている面のエッジを入れ、その両側のスロットをF2Lの要領で揃えていけば良い。
一例。

14のスロットは、 F' して15の位置にし、スロットインした後に F で戻す。
S2Lの重要なこととして、基本的に順番は固定する。 次のスロットのペアがすでに揃っていたら先に入れるとか多少の入れ替えは良いと思うけど。
任意の順番にして手数の短いスロットが選べることよりも、先読みがしやすいことのほうがメリットが大きいのだと思う。 特に、順番を固定するということは、あるスロットに取り組んでいるときにすでに揃っている部分も固定になり、そこからはピースを探さなくて良いというのが大きい。
F2LとS2Lがメガミンクスの面白いところだと思うし、ここでタイムに大きな差が付きそう。
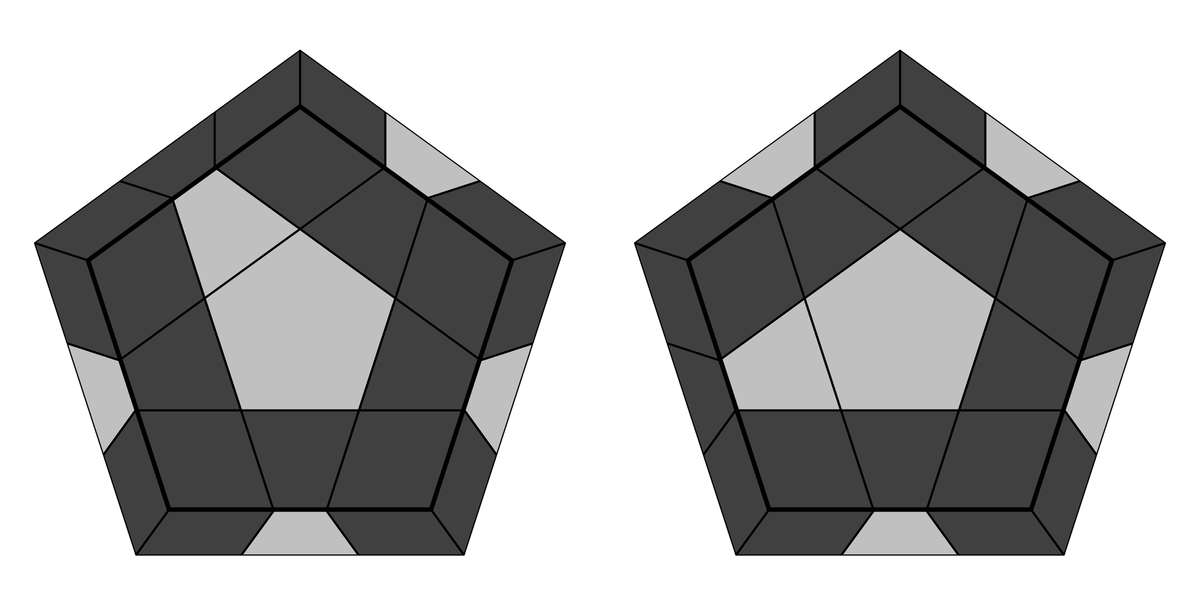
OLL(エッジ)
2個のエッジが反転している場合が2パターン、4個のエッジが反転している場合が1パターンの3パターンしかない。

左は F R U R' U' F' 、右は F U R U' R' F' 。 それぞれ下の3x3x3のOLLと同じ。 6手OLL。
4個反転している場合。 左の向きから、6手OLL、 U2 、6手OLLの (F R U R' U' F') U2 (F R U R' U' F') 。 専用の手順を覚えるのであれば、右の向きから、 F R U2 R2' F R F' U2' F' 。 5角形なので、 R2' と R2 などは異なることに注意。
OLL(コーナー)

最大2回のSune系の手順でとりあえず揃えることはできる。
3個のコーナーの向きが合っていない3COは次の4パターン。
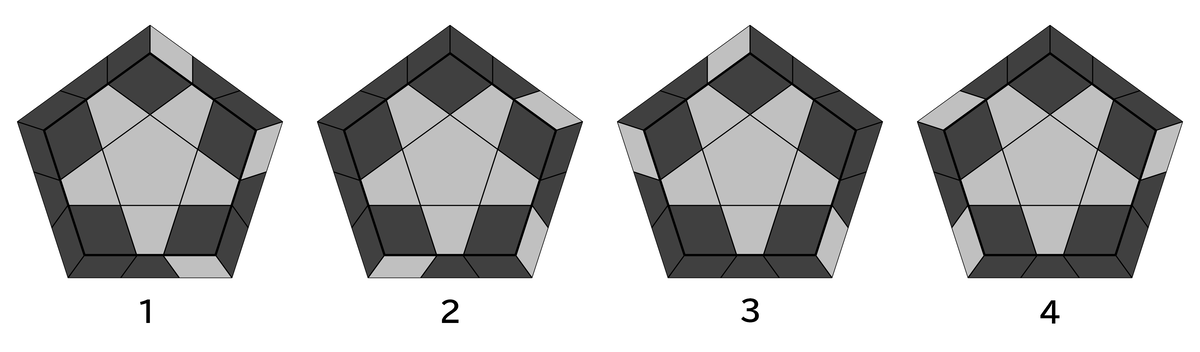
それぞれ次の手順で揃う。
- 1: R U R' U R U2' R'
- Sune
- 2: R' U' R U' R' U2 R
- 1を前後反転した手順
- 3: R U2 R' U' R U' R'
- 1の逆手順
- 4: R' U2' R U R' U R
- 2の逆手順
3x3x3では、1と4、2と3は同じ結果になるが、メガミンクスでは異なる。
3と4の向きがちょっと覚えづらい。 私は、1個離れているコーナーのU面色をR面に向けて、向きの合っていない2個のコーナーの向きを変えるのだから、それらをR面に放り込むと考えている。
2個のコーナーの向きが合っていないときは、そのうちの1個と、向きの合っている2個のコーナーを、向きの合っていない1個の向きを合わせるように回せば3COになる。
4個のコーナーの向きが合っていないときは、向きの合っていないコーナーのうち任意の3個を選ぶと、必ず1個だけ回転方向が異なる(4個のコーナーの向きがあっていないとき、時計回りと反時計回りが2個ずつなので)。 その1個の向きを合わせるように回せば3COになる。
5個のコーナーの向きが合っていないときは、1個が時計回りで2個が反時計回りか、1個が反時計回りで2個が時計回りの3個のコーナーを選び、2個を揃えるようにする。 なお、側面に2個のコーナーのU面色が並んだヘッドライトがあれば、その2個のコーナーは回転方向が異なる。
Sune系最大2回ではなく、1回の手順で揃える方法はこの記事に載っている。 以降のPLLの手順なども載っている。
「エッジも含めてOLLを1 lookにするぞ💪」というなら次の記事を参照。 まあ、3分とかのタイム帯の人が取り組むことではないだろう。
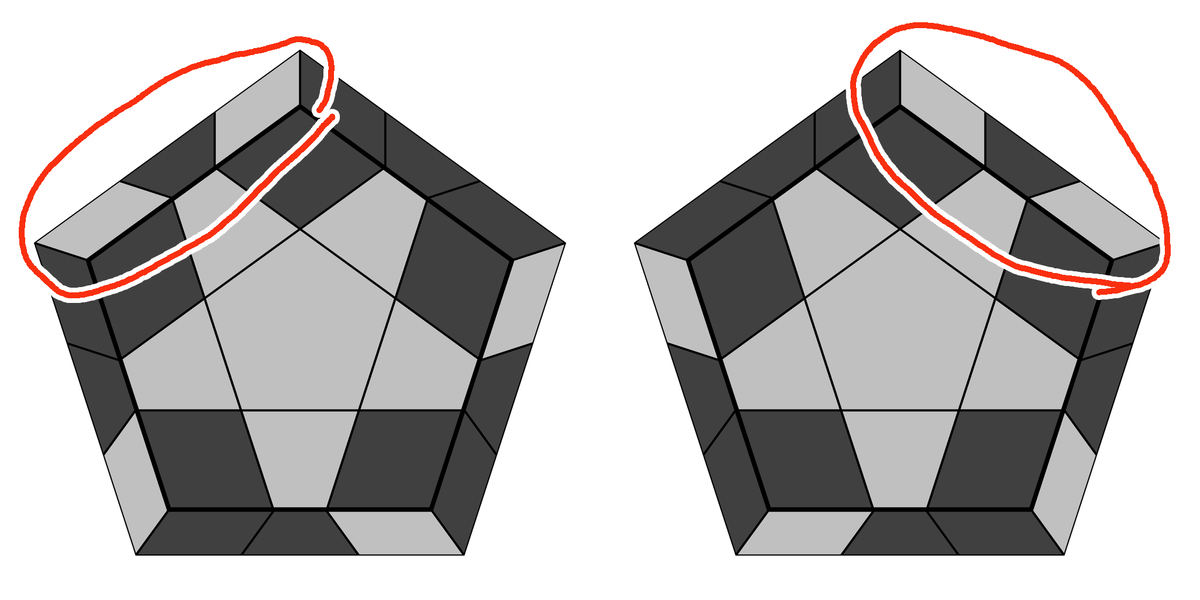
PLL(エッジ)

3x3x3のJbパームで良く知られた手順である R U R' F' R U R' U' R' F R2 U' R' で、図の左のようにエッジが時計回りに動く。 反時計回りのときは、この手順を反転するか、逆にするか、2回繰り返すか……などと思うかもしれないが、実は、この手順は図の左のようにエッジを反時計回りに動かす手順でもある。 5角形面白い。
この手順を何回か使ってエッジのPLLを完了することはできる。 でも、残りは2パターンしか無いので、他の手順も覚えておくと良いだろう。

R2 U2' R2' U' R2 U2' R2' で図の左のようにエッジが時計回りに動く。 R2 でオレンジのエッジを退避し、 U2' でオレンジのエッジを入れる場所を持ってきて……というイメージ。 この手順は、図の右のようにエッジを反時計回りに動かす手順でもある。 こちらは前後反転や逆の手順も簡単なので、それらでも良いかもしれない。

2点交換×2。
何かしら3点交換の手順を回すと3点交換の状態になるので、とりあえずそれで揃えることはできる。
1度で揃える手順は R U R' U (R2 U2' R2' U' R2 U2' R2') U2' R U' R' 。 R U R' U の後、上の2個目の3点交換の手順を回して U2' 、出ているS2Lペアをスロットインする。 この手順は、U面がどの向きでもOK。
判断方法。 3点交換の状態のとき、U面を回してくと、2箇所で2組のエッジと側面センターが合い、2箇所で1組も合わず、1箇所で1組だけ合う。 2点交換×2は、U面がどの向きでも、1組のエッジと側面センターが合った状態になる。 ということで、次のように判断できる。
- 適当にエッジと側面センターを合わせる
- 5組のエッジと側面センターが合っていたら完成状態なので終了
- 2組のエッジと側面センターが合っていたら、3点交換
- 1組だったら、1で選んだものとは別のエッジと側面センターを合わせる
- 2組のエッジと側面センターが合っていたら、3点交換
- それでも1組だったら2点交換×2
4の時点で、合っていないエッジの入れ替わり方を見て、2点交換×2かどうかを判断しても良いかもしれない。
PLL(コーナー)

1個ずつコーナーを揃えていく。

U? (R' FR' R) U? (R' FR R') U? (R' FR' R) U? (R' FR R') ... という動きで揃えていく。 偶数回目は FR' が FR になることに注意。
最初のU面の動きで、合っていないコーナーxを位置URFに持ってくる。 R' FR' R でコーナーxが下段に退避される。 コーナーxがあるはずの位置をURFに持ってきて、 R' FR R でその位置にコーナーxが戻り、URFにあったコーナーyが下段に移動する。 コーナーyがあるはずの位置をURFに持ってきて、 R' FR' R ……と繰り返す。 必ず偶数回目で終わる。 もし奇数回になったら、揃わない状態になっているので、分解して直す必要がある。
目隠しでURFバッファを使いコーナーを揃えていくイメージ。 あるいは、コミュテーター [U?, R' FR' R] を繰り返していくと考えても良い。
↓ステップごとの詳しい説明がある。
1個ずつではなくまとめて揃える手順。
この記事のうち、エッジが揃っているものの説明も合わせて読むと良い。
3CPの手順がなんか自然な感じがしなくてなかなか覚えられなくて心が折れかけたが、4CPや5CPのほうがむしろ楽に覚えられる手順が多かった。
画像
ステッカーの色を指定してメガミンクスの画像を生成するツールが見つからず、スクリプトを書いたらけっこう面倒だった。 置いておくのでご活用ください。
https://gist.github.com/kusano/2c2e7f075a7f55c126b96e89b7759be2
LLならツールがある。
WCA公式大会のFMCで最短解を出した人は何人いるのか?
2025年6月22日現在、次の16人。
- Chad Batten (2009BATT01)
- GA Cubers Mountain Trip 2018, Second round, 第3試技, 18手
- Harry Savage (2013SAVA01)
- The Great British Blind Off 2019, First round, 第3試技, 17手
- Sebastiano Tronto (2011TRON02)
- FMC 2019, Final, 第1試技, 16手
- Cale Schoon (2014SCHO02)
- North Star Cubing Challenge 2020, Final, 第2試技, 18手
- Wong Chong Wen (黄崇文) (2014WENW01)
- Mental Breakdown Singapore 2024, Final, 第1試技, 18手
- FMC in Bali: Pura-Pura Mencari Solusi 2024, First round, 第2試技, 18手
- Levi Gibson (2018GIBS04)
- Ashfield Summer Challenge 2024, Final, 第2試技, 16手
- Aedan Bryant (2017BRYA06)
- Ashfield Summer Challenge 2024, Final, 第2試技, 16手
- Jan Riedl (2019RIED01)
- Rubik's WCA European Championship 2024, Final, 第1試技, 18手
- Kyeongmin Choi (2017CHOI07)
- Korean FMC Championship 2024, Final, 第2試技, 18手
- Yunqi Ouyang (欧阳韵奇) (2007YUNQ01)
- Korean FMC Championship 2024, Final, 第2試技, 18手
- Daniel Karnaukh (2014KARN02)
- New York Quiet Championship 2024, Final, 第3試技, 18手
- Jacob Sherwen Brown (2022BROW01)
- Rubik's UK Championship FMC 2024, Final, 第3試技, 16手
- Radomił Baran (2020BARA02)
- Europe FMC Friends - Winter 2025, Final, 第1試技, 18手
- 5BLD Masters Opole 2025, Final, 第3試技, 17手
- Wojciech Rogoziński (2019ROGO04)
- Europe FMC Friends - Winter 2025, Final, 第1試技, 18手
- Enrico Tenuti (2017TENU01)
- Europe FMC Friends - Winter 2025, Final, 第1試技, 18手
- Firstian Fushada (符逢城) (2015FUSH01)
- Singapore Championship 2025, Final, 第2試技, 17手
FMC(Fewest Moves Challenge、最少手数競技)とは、ルービックキューブの手数の少ない解法を、キューブと紙とペンを使って人力で1時間以内に探す競技である。
キューブはどんな状態からでも20手で解けることが知られているが、20手掛かる状態というのはとても少ない。 全体の0.0000000011 %しかない。 8手以下になる確率より低い。 割合は次の通り。 https://www.cube20.org/ の数値から割合を計算した。 なお、16手以降はおおよその値らしい。
| 手数 | 割合 |
|---|---|
| : | : |
| 14 | 0.02 % |
| 15 | 0.21 % |
| 16 | 2.54 % |
| 17 | 27.74 % |
| 18 | 67.05 % |
| 19 | 3.47 % |
| 20 | 0.0000000011 % |
2025年現在の人類のレベルは、トップ層の人が稀に真の最短解と同じ手数を見つけることができるくらい。 ……というのは聞いたことがあるけれど、実際何人が最短解を見つけているのかが気になって調べた。
結果とスクランブルは公開されているのでクローラーを書いて……ということはしなくても、DBのダンプが公開されている。 ありがたい。
これをSQLiteに読み込んで……と思ったら、MySQL用で、非互換なところがあるらしく、ダメだった。 まあ、TSVで良いだろう。
スクランブルは最短の手数というわけではないので、最短解を探す必要がある。 これはコンピューターでもちょっと難しく、雑にプログラムを書くと終わらない。 Nissy を使った。 このプログラムは、数十分掛けて数GBのテーブルを作り、それを使って最短解を数分くらいで探してくれる。 そう、コンピューターでも、ちゃんと作られたプログラムでこのくらいは掛かる。 これを人力で見つける人はすごい。 最短であることが保証された解を探すのと、なるべく短い解を探して実はそれが最短だったという違いはあるけれど。
nissy-# というプロンプトが出力されなくてちょっとハマった。
setbuf で標準出力のバッファリングを無効化する必要がある。
20手以下の結果について、最短解と手数が一致しているかどうかを調べた。 前述のように最短解が20手であることはまずないので、20手は調べなくても良い気はするが、一応。
プログラムと結果。
16手の記録が出たFMC 2019は、Extraのスクランブルがあり、各選手の試技がどのスクランブルかが分からなかった。 しかし、本人がこの記録を紹介している。
Czech Open 2012はスクランブルが公開されていない。 でも、20手なので、ほぼ確実に最短解ではないでしょう。
Tokyo FMC Spring 2025参加記
FMCとは?
Fewest Moves Challenge、最少手数競技。「ルービックキューブで世界新記録!」みたいなのはいかに速く解けるかを競っているが、この競技はいかに短い手数で解けるかを競う。 お題が与えられ、1時間の時間制限の中で、紙とペンとキューブを使って、なるべく短く解く手順を見つけて提出する。 これを3回やって、平均が一番短い人が勝ち。
3x3x3キューブはどんな状態からでも20手で解けるということが知られているが、20手掛かる状態というのはとてもレアで、ランダムに生成したら0.000000001%くらいの確率でしか出てこない。だいたいは18手か17手、数%くらいで16手か19手という感じ。
トップの人は人力でこの真の最短解+数手の解を人力で見つけるからすごい。 ちなみに、普通にキューブを解くとだいたい60手くらいになる。
解き方は普通にキューブを解くのとは全く異なる。 どんな解き方をしているのかはこの辺を見ると良い。
1個目のほうは全体的にまとまっているが、解法が古い。 1個目の「付録D: ドミノリダクション入門」の解法が2025年現在の主流。
要は各ステップで色々と試行錯誤をする。 その中でときどきそのステップの短い手順が出てくる。 ガチャのように射幸心が煽られて楽しい。
宣伝
とらのあなに販売委託していたけれど、すでに終了してしまっている。 そのうち在庫が送り返されてくるらしい。
5月末からの技術書典18でも頒布する予定なので、よろしくお願いします。 イベント自体が通販もやっているので、ネットでも買える。
あと、このFMCの各ステップをコンピューターで解くツールも作ったので使ってほしい。
目標
平均30手未満。 こんなことを言っていて、まさか3か月後にまたFMCの大会があるとは思わなかった。
平均sub30はいずれどこかで……。しかし、FMC、もう1段階何か技術革新があったら、上位陣は真の最短解が当たり前になって、競技自体が終わりそう。私が平均sub30するのが先か、競技が終わるのが先か。
— kusanoさん@がんばらない (@kusano_k) 2025年2月16日
持ち物
スマートウォッチではない腕時計があると良い。 試験みたいなものなので、電子機器は使用不可。 前に時計は置かれていたけれど、やはり手元で見たい。
あと、キューブによってはセンターキャップを外す器具。 「キューブをチェックします。センターキャップを外して見せてください」と言われた。 Bluetoothでスマホと繋がるキューブがあるので、そういうものではないか確認すると。 最近のGANのキューブは専用の器具が無いと外せない。 「この競技でキューブのメンテをしたくなることないだろ。でも、まあ、一応持っていくか」と持っていっていて良かった。
第1ラウンド第1試技
スクランブル。
R' U' F U2 R2 F R2 D2 U2 B R2 B' L U B' F R D' R2 B U2 L2 F R' U' F
4手EOが1個も無い。 なんだこのスクランブル……。 出鼻がくじかれる。
……と、本番中は思っていたけれど、今ソルバーに掛けたら4手EOが3個あったわ。
- L (F2 B R)
- D (B' R' D)
- (R' D) L' D
3個目の2+2手のものは仕方が無いにしても、1個目と2個目は見つけられても良かった……というかこの形のものはチェックしていたはずだけど……。 見落としていたらしい。 こういうことを大会が終わった今やっていてももう遅く、大会前の練習のときから、解いた後にツールを使って見落としが無いかチェックしておくべきだった。 反省。
見つけたDRは、15手2c5、14手2c4、14手2c4、17手2c4。 このステップも今ひとつ。
まあ、選ぶなら14手2c4だろうな。 HTRまではHT(Half Turn、180度回転)ほぼ最少でいけて悪くない。 HTR以降もすんなりleave sliceにいけて、VR状態だった。
スライスインサートで+1手で31手。 良くはないけど、まあスクランブルの運も悪いだろうし、「あれ、書いた手順で揃わない? なんで???」みたいに慌てることもなく、時間に余裕を持って何度かチェックもできたし、良い感じ。
B L R2 D' F' // EO (F/B) (5/5) // DR-4e4c (R/L) (0/5) R D2 F2 R' F2 R U2 R' U // DR (R/L, 2c4) (9/14) B2 R F2 R' F2 R F2 R * // HTR (8/22) B2 U2 R2 * // FR (R/L) (3/25) B2 U2 B2 D2 F2 // LS (R/L, VR) (5/30) * = E2 // finish (1/31)
B L R2 D' F' R D2 F2 R' F2 R U2 R' U B2 R F2 R' F2 R F2 R' L2 F2 D2 L2 B2 U2 B2 D2 F2
第1ラウンド第2試技
スクランブル。
R' U' F D' B2 L2 B U R' D' L' U2 F2 R B2 D2 L B2 L B2 L F2 B' R' U' F
見つけたDRは、16手4b3or4、16手4a2、16手2b5、16手2c4。 だめだこりゃ。 だめだし、DR探索をねばって時間が無くなってしまったのが良くない。 結局2個目に見つけた16手4a2を選択し、HTRを探索する時間が無くて、ほぼそのまま解いただけ。 36手。 つらい。
(F L R2 B) // EO (F/B) (4/4) (R U) // DR-4e4c (R/L) (2/6) (L B2 L' U2 R' U2 R U2 L U) // DR (R/L, 4a2) (10/16) R2 B2 R * D2 R2 F2 D2 B2 D2 B2 D2 B2 R' * // HTR (13/29) B2 R2 B2 D2 R2 + // FR (R/L) (5/34) D2 U2 // LS (R/L) (2-1/35) * = M', + = M2 // finish (1/36)
R2 B2 L B2 R2 D2 B2 U2 B2 U2 B2 U2 R2 L F2 R2 F2 U2 L2 D2 U L' U2 R' U2 R U2 L B2 L' U' R' B' R2 L' F'
第1ラウンド第3試技
スクランブル。
R' U' F L2 D' B2 R2 B2 F2 U F2 U' F R F2 D' R B2 L2 D R F R' U' F
疲れているのか運が悪いのか分からないけど、RZP(DR-XeXc)からのDRが、手数が長くなりそうなものばかり。 17手4a3と19手4a3を見つけただけ。 17手4a3からのleave sliceが35手。
まあ、しょうがないか……とスライスインサートをしたけど、なんか揃わない。 やばい。 結局、書いた手順を間違えていたわけではなく、手順を回すときに間違えていたっぽい。 もう時間が無いから、スライスインサートではなく、普通にスライスを揃えた。 41手。
DNFにならなかっただけマシか。 基本的には平均で競うので、DNFが1個でもあると、その時点で最下位になってしまう(DNFがある人同士の中では、DNF以外のベストの記録で順位が付く)。
(R) U F' B2 R' // EO (R/L) (5/5) F' D // DR-4e4c (F/B) (2/7) U2 L2 B2 R2 F U2 F' R2 B2 D // DR (F/B, 4a3) (10/17) F L2 F2 D2 F' D2 L2 U2 L2 B' // HTR (10/27) U2 F2 R2 U2 F2 // FR (F/B) (5/32) R2 D2 L2 // LS (F/B) (3/35) U2 F2 B2 D2 F2 B2 // finish (6/41)
U F' B2 R' F' D U2 L2 B2 R2 F U2 F' R2 B2 D F L2 F2 D2 F' D2 L2 U2 L2 B' U2 F2 R2 U2 F2 R2 D2 L2 U2 F2 B2 D2 F2 B2 R'
決勝進出
31手、36手、41手で平均36手。 これは決勝進出無理かなぁと思ったけど、通っていた。 良かった。 単発記録も平均記録も自己ベストを更新できていないので、これで終わりは悲しい。
決勝進出ラインは、ほぼ、DNF無しで平均記録を残せたかどうかだった。 「皆、キューブを普通に解くことはできるんでしょ? DNFにしないだけなら簡単では?」と思われるかもしれないけど、これが意外と難しい。 特に焦っていると、書いた手順を回してみても揃わなくてどうしようもなくなる。 やってみると分かる。
なお、決勝進出は上位75% それなら単に全員2ラウンドで良くない? と思うかもしれないけど、これが主催者の裁量で可能な上限。 ラウンド数などは主催者が好き勝手にできるわけではなく、WCAの定めるレギュレーションがある。 例えば、競技者が100人未満だったら4ラウンド制にすることはできない。 その中に各ラウンドでは少なくとも25%の競技者を除外しないといけないというルールがある。
1回の大会で良い順位を取ることよりも、記録を残すことを目的にする人は多い。 そういう競技者にとっては「この大会は10ラウンド制! 全員次のラウンドに行けます! 要は10回挑戦できます!!!」みたいな大会があると嬉しいし、そういう大会も開かれるだろう。 でも、そんな何回も挑戦して出した記録で「世界新記録です!」というのは違うのでは? ということなのではなかろうか。
決勝第1試技
スクランブル。
R' U' F U2 R2 F R2 D2 U2 B R2 B' L U B' F R D' R2 B U2 L2 F R' U' F
4手EOがそのままDR-4e4cになっていて、それが簡単にDRにできて9手4b2。 決勝進出者へのご褒美感ある。 これ、大会の記録での自己ベストどころか、家での練習も含めても自己ベスト狙えるのでは? と思ったけど、FR以降は今いちだった。 25手。 まあ、充分でしょう。
(F L' D2 B') // EO (F/B) (4/4) // DR-4e4c (U/D) (0/4) (L2 U' B2 D L') // DR (U/D, 4b2,6e) (5/9) (U2 B2 U' * F2 D') // HTR (5/14) (R2 U2 * B2 L2 B2 R2 B2 R2 U2) // FR (U/D) (9/23) (L2) // LS (U/D, VR) (1/24) * = E2 // finish (1/25)
L2 U2 R2 B2 R2 B2 L2 B2 D2 L2 D B2 U' D2 B2 U2 L D' B2 U L2 B D2 L F'
終わった後に聞き耳を立てていたら「9手4b2が~」という話があちこちから聞こえてきた。
決勝第2試技
スクランブル。
R' U' F L2 B' F' U2 F' U2 L2 F U' F D U' R2 F R' U R' U F2 R' U' F
見つけたDRで一番良いのが11手2c4。 そこから29手。 良くも悪くもなくというか、実力通りというか、これがコンスタントにできればとりあえず満足感がある。
D R U // EO (U/D) (3/3) L F // DR-4e4c (R/L) (2/5) D2 R' L U2 R F // DR (R/L, 2c4) (6/11) (R D2 R' %) R2 B2 U2 R' * U2 R + // HTR (9/20) U2 F2 U2 R2 // FR (R/L) (4/24) F2 B2 D2 B2 // LS (R/L) (4/28) * = M2, + = M', % = M // finish (1/29)
D R U L F D2 R' L U2 R F R2 B2 U2 R L2 D2 L B2 U2 B2 R2 U2 D2 F2 D2 L D2 R'
決勝第3試技
R' U' F R2 D' L2 D2 R2 U' B2 U' F2 L D' F L' F' U' R2 U2 L U R' U' F
11手4a3or4、10手2c4、11手2c4、13手2c5。 悪くはないけど……と思っていたらDR探索の最後のほうで9手4b2を見つけた。 ラッキー。
そこから29手とか27手とかになっていたけど、スイッチしてみたら、14手HTRからの24手leave slice。 第1試技の記録を更新できるのでは? と期待したが、スライスインサートが+2手だった。 VRを使い始めて以来、初めてこのパターンを見た。
解答を書き下して、DR以降を末尾に移動するとこうなる。
U2 U2 D U' B2 R2 R2 F2 L2 F2 L2 B2 F2 R2
簡略化。
F2 R2 || F2 || F2 | F2 R2 |
+0手で反転できるのが最後の区間しかなく、反転するとVR化する。 これと、 E2 を挿入したときの影響は次の通り。
U2 U2 D U'
B2 R2 R2 F2 L2 F2 L2 B2 F2 R2
E E
f g f g
エッジは完成状態でセンターが反転しているので、和がdotになるように奇数回の E2 を挿入する必要がある。
r があれば、 r+f+g=t でいけるけど、無いので無理。
U2 U2 D U'
B2 R2 R2 F2 L2 F2 L2 B2 F2 R2
E E
f r g f r g f r g
E2 E2 E2
こうして+2手。
今にして思うと、+1手でVR化し、その後+0手で完成させられる可能性はあったか。 とはいえ、ソルバーに掛けてみても+2手しか無かった。
(U2 R' F) // EO (F/B) (3/3) U R // DR-4e4c (U/D) (2/5) D L2 U' L // DR (U/D, 4b2) (4/9) (U * R2 F2 D' *) // HTR (4/13) (B2 U2 * L2 F2 L2 F2 R2 * U2 *) // FR (U/D) (8/21) (L2 B2 R2) // LS (U/D) (3/24) * = E2, + = E' // finish (2/26)
U R D L2 U' L R2 B2 L2 D2 L2 U2 D2 F2 L2 F2 L2 D2 F2 U R2 B2 D' F' R U2
まとめ
予選は全然だめだったが、決勝は普段より上振れた感があって良かった。
今後。 まずは正確性を上げることか。 いちいち書かなかったが、わりと良くできた決勝でも「あれ、揃わない。おかしいな」ということは度々あった。
私より上の人達、私が「今回はすごくラッキーだった」という手数が、「最悪でもこのくらいは」という手数である。 どうすればそうなれるかというと、探索の物量っぽい。 たぶん、私の10倍くらいの量を探索している。
判断強化とスピードだと思います
— うえしゅう (@uesyuu_cube) 2025年4月20日
EOを8分で数十個書くスピード、RZPを探すスピード、RZPが使えるか判断するスピード、HTRの基本的なルートを漏れなく全て探すスピード、HTRの良し悪しを判断するスピード…
やる事はシステマチックに決まってるからこそスピードで量を稼ぐ必要があるのかと
あと5手くらいというと小さく思えるが、そもそも真の最短解よりは縮まず、真の最短解+4手くらいと真の最短解+9手くらいと考えると差は大きい。 1手縮めるのに倍くらいの探索量が必要なのではという感覚がある。
しかし……「FMCはスピード競技と違ってじっくり考えられるから良いね」と思っていたが、1周回ってスピード競技に戻ってきた感が……。
おまけ
大会の翌日にこの記事を書いている。 昨日は1時間×6回=6時間の試技をした。 大会に出るような人でも、1日6回も練習をすることはまず無いらしい。
で、6時間机に齧り付いているとどうなるか? 今、筋肉痛で首と肩が痛い。 動かなくても筋肉痛になるんだ……。 体力も重要なのかもしれない。
【FMC】Hyper-ParityからHTR Subsetsに乗り換えたい【ルービックキューブ】
HTR Subsetsのほうが簡単なので。簡単な分、U2の回数も考慮して状態を分けられるので、その辺をメモしておく。
Hyper-Parityとは
この辺を参照。 要は、U/D面の状態とF/Bの状態の組み合わせについて、どのような遷移が可能かまとめるとHyper-Parity Mazeになり、偶奇が合うようにSolvedな状態に向かうと、コーナーのHTRが完了する。
HTR Subsetsとは
HTR Subsetsでは、0c3や4b2のような3文字で状態を表す。 先頭の2文字には、0cと4a、4b、2cがあり、それぞれHyper-ParityのF/B面のSolved、One Face、Bars、One Barに対応している。 先頭の数字はバッドコーナーの個数。 2文字目の英字は、バッドコーナー4個のOne FaceとBarsを区別するためだろう。 末尾の数字はQT数。 QT数なのでQTの偶奇の情報も含まれており、Hyper-Parityのように各状態に偶数と奇数が別にあるわけではない。
無理矢理分けているようにも思えるが、例えば2c4に含まれるある状態からは2c3に遷移できるが別の状態からは遷移できないというようなことは一切無い。 もしかすると、U/D+F/B=Bars+Barsが3個の状態に分かれたりするHyper-Parityよりも本質的なのかもしれない。
HTR Subsetsの判別
Hyper-ParityのF/B面の状態とQT数なので、Hyper-Parityを知っていれば、HTR Subsetsのどの状態かを判別することはできる。 Hyper-Parityの各状態について、偶奇別のQT数は次の通り。

しかし、もっと覚える事が少ない方法がある。
まずはF/B面の状態から、先頭の2文字を特定する。 その後、次のようにしてHTR Subsetsの状態が分かる。
0c
Hyper-ParityのU/D面がSolveかどうかを、F/B面とR/L面についても見る。 Solvedなものが0個ならば0c4、1個ならば0c3、2個になることはなく、3個ならば0c0。 BLDトレースは不要。 なぜこれでパリティを含めて判別できるのかが分からない……が、便利。
2c
バッドコーナーを2個を頭の中で入れ替えて、0cと同様のことをする。 0個ならば2c3、1個ならば2c4、3個ならば2c5。 揃っている個数とQT数が0cとは逆になる。
4a, 4b
BLDトレースでQT数の偶奇を求める。 また、normal方向とinverse方向で4aと4bのどちらになるかを調べる。 バットコーナーの側面色を見て、側面色が同じものをペアにしたとき、ペアが1組なら逆方向は4b、0組か2組ならば4a。 どちらも4aならばQT数は1か2、4aと4bならば3か4、4bと4bは5か6……ではなく、2か5。
HTR Subsetsの遷移
下図のように遷移する。
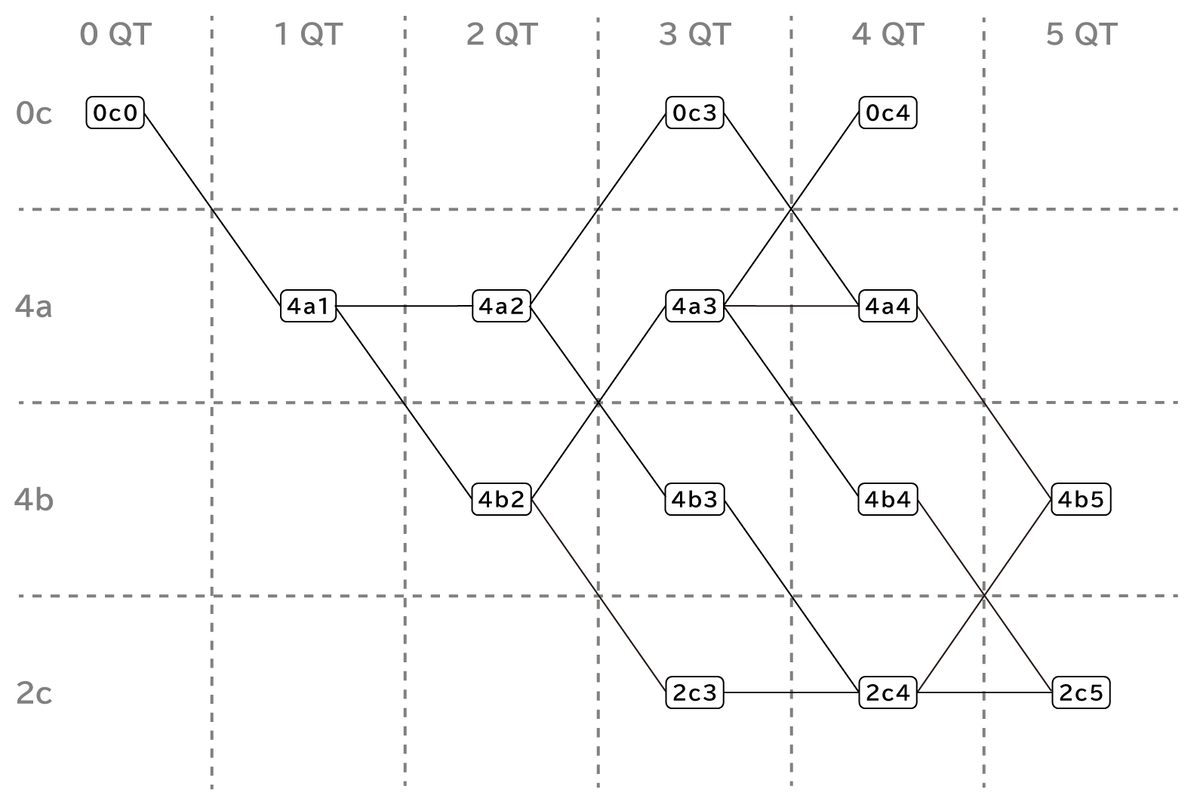
ところで、QT数が同じだからと言って、HTR完了までの手数の期待値が同じとは限らない。 例えば、2c3 → 4b2 → 4a1 → 0c0 は最短5手でHTRが完了する。 一方、0c3 → 4a2 → 4a1 → 0c0 は途中に2回のU2が必ず入り、最短でも9手。
HTR SubsetsではU2で遷移するものは同じ状態として扱うけれど、これを別にすればより正確になるのでは? と思ってやってみた。 こうなった。

https://gist.github.com/kusano/edc2607bb41d97d4592086809bbc993c
+ と - はHTR完了までが近いかどうか。
その後の a と b は区別するためだけで特に意味は無い。
横軸をQT(U/U')ではなく、U2も含めた回数にするとこうなる。

基本的には最短手数を目指すことになるので、縦方向の遷移は省略して良いだろう。 また、4a3+aと4a3+bが分かれていることで、0c4 → 4a3 → 4b4にはU2が必要なことが分かるが、こんな遷移はしないので、4a3+aと4a3+bはまとめてしまって良いだろう……など整理すると、こうなった。

これを覚えれば良いのではなかろうか。
解き方
上の図にしたがって解くとき、HTR Subsetsの各状態で行うこと。
多くの状態は、単にF/B面を目指す状態にすれば良い。 そのような状態は次の通り。 例えば、4b3は、4aにすると必ず目指したい4a2になる。4a4にはならない。
| from | to |
|---|---|
| 0c4 | 4a3 |
| 4a1 | 0c0 |
| 4a2 | 4a1 |
| 4a4 | 4a3 |
| 4b3 | 4a2 |
| 4b4 | 4a3 |
| 4b5 | 2c4 |
| 2c3 | 4b2 |
| 2c5 | 2c4 |
遷移する方法は次の通り。
- 0c → 4a
- U/U'で常に遷移する
- 4a → 0c
- バッドコーナーをU面かD面に集める
- 4a → 4a
- バッドコーナーをFLとBR、もしくはFRとBLの対角線に集める。U/U'でU面のコーナーがバッドかどうかが切り替わるので4aのまま
- 4a → 4b
- バッドコーナーをU面とD面に2個ずつにする
- 4b → 4a
- バッドコーナーをU面とD面に2個ずつにする
- 4b → 2c
- バッドコーナーをU面とD面で1個と3個に分ける
- 2c → 4b
- バッドコーナーをU面とD面に1個ずつにする
- 2c → 2c
- 2個のバッドコーナーをU面かD面のどちらか一方に集める
F/B面の状態だけ見ていると悪い方向にも行く可能性がある場合が厄介。
0c3
4a2に行きたいが、単に4aにするだけだと4a4になりうる。
- U/D面がSolved
- U面の対角同士が同じ色はOK
- U面が全て同じ色はOK
- U面の隣接が同色のバーはNG
- U/D面がBars
- U面の色が2個ずつはOK
- U面の色が1個と3個はNG
遷移してみて、NISSしたバッドコーナーの配置が4aなら4a2という判断でも良さそう。
4a3
バッドコーナーをU面とD面に2個ずつにして、4b2に行きたい。 4b4になる可能性がある。 バッドコーナーを2個ずつにしたときにU/D面の状態に応じて次のようになっていれば良い。
- U/D面がSolved
- U面が全て同じ色はOK
- U面にバッドコーナーのバーがあり、バッドコーナーのU面が異色はOK
- U面にバッドコーナーのバーがあり、バッドコーナーのU面が同色はNG
- U面の対角同士が同じ色はNG
- U/D面がBar/Slash
- U面の色が2個ずつはOK
- U面の色が1個と3個はNG
遷移してみて、NISSしたバッドコーナーの配置が4bなら4b2という判断でも良さそう。
4b2
バッドコーナーをU面とD面に2個ずつにして、4a1に行きたい。 4a3になる可能性がある。 バッドコーナーを2個ずつにしたときにU/D面の状態に応じて次のようになっていれば良い。
- U/D面がSolved
- U面が2色はOK
- U面が全て同じ色はNG
- U/D面がBars
- バッドコーナーのU面が同色はOK
- バッドコーナーのU面が異色はNG
- U/D面がBar/Slash
- U面の色が1個と3個はOK
- U面の色が2個ずつはNG
遷移してみて、NISSしたバッドコーナーの配置が4aなら4a1という判断でも良さそう。
2c4
2c3に行きたいが、2c5になりうる。
バッドコーナーをU面かD面に集めてUかU'を回した後、バッドコーナーを入れ替えて、U/D面がSolvedになってなければOK。
2cへの遷移は、2c3か2c5になる。 判別法のところで見たように、2c3ならSolvedな軸は0個、2c5なら3個なので、どれか1面を見れば良い。 U/D面が簡単。
NISS
NISSのスイッチでどの状態に切り替わるのかを調べてみたら面白いかと思ったが、特に面白いことは無かった。

4a3と4b3、4a4と4b4が切り替わる以外は、同じ状態の中のどこかに切り替わる。 QT数もバッドコーナーの個数も変わらない。 Normal方向で最後に回した180度回転は、inverse方向では初期状態からの180度回転になり、これはHTR的な状態を変えないので、そりゃそうか。 4a3と4a4で次の状態に進むためにU2が必要ならスイッチすると得。 それ以外のU2が必要なときは、得するかもしれないし、しないかもしれない。
NISSといえば、例えば、
(A U) B U2 (C U') D U // HTR
このように解いたとき、これは次のようにも解ける。
(A U C U') B U2 D U // HTR B U2 D U (A U C U') // HTR
NISSの括弧の中は、最後はまとめて逆手順を付け足すことになるので、どこにあっても同じ。 しかし、4aと4bが絡むようなときは、HTR subsetsの推移としては別になるはず。 この辺何か面白い話はないだろうか。
Hyper-ParityのU/D面とF/B面の状態は全く同じという話
乗り換えようとしているので、最後に。 何となく似ているようだが、似ているどころか全く同じである。
コーナーを、(UBL, UFR, DBR, DFL), (UBR, UFL, DBL, DFR) の2グループに分ける。 グループ内のキューブが同じグループ内のどこかにあるときグッドコーナーになり、別のグループの位置にあるとバッドコーナーになる。

キューブをこのように塗り分けて、赤を赤のところに、緑を緑のところに配置すると、F/B面がSolvedの状態になる。 これは、赤をU面色、緑をD面色と見なすと、U/D面のSlashesと同じ配値。 U/D面のSolvedの配置にすると、F/B面の状態としてはOne Faceになる。 BarsならBars、Bar/SlashesならOne Bar。
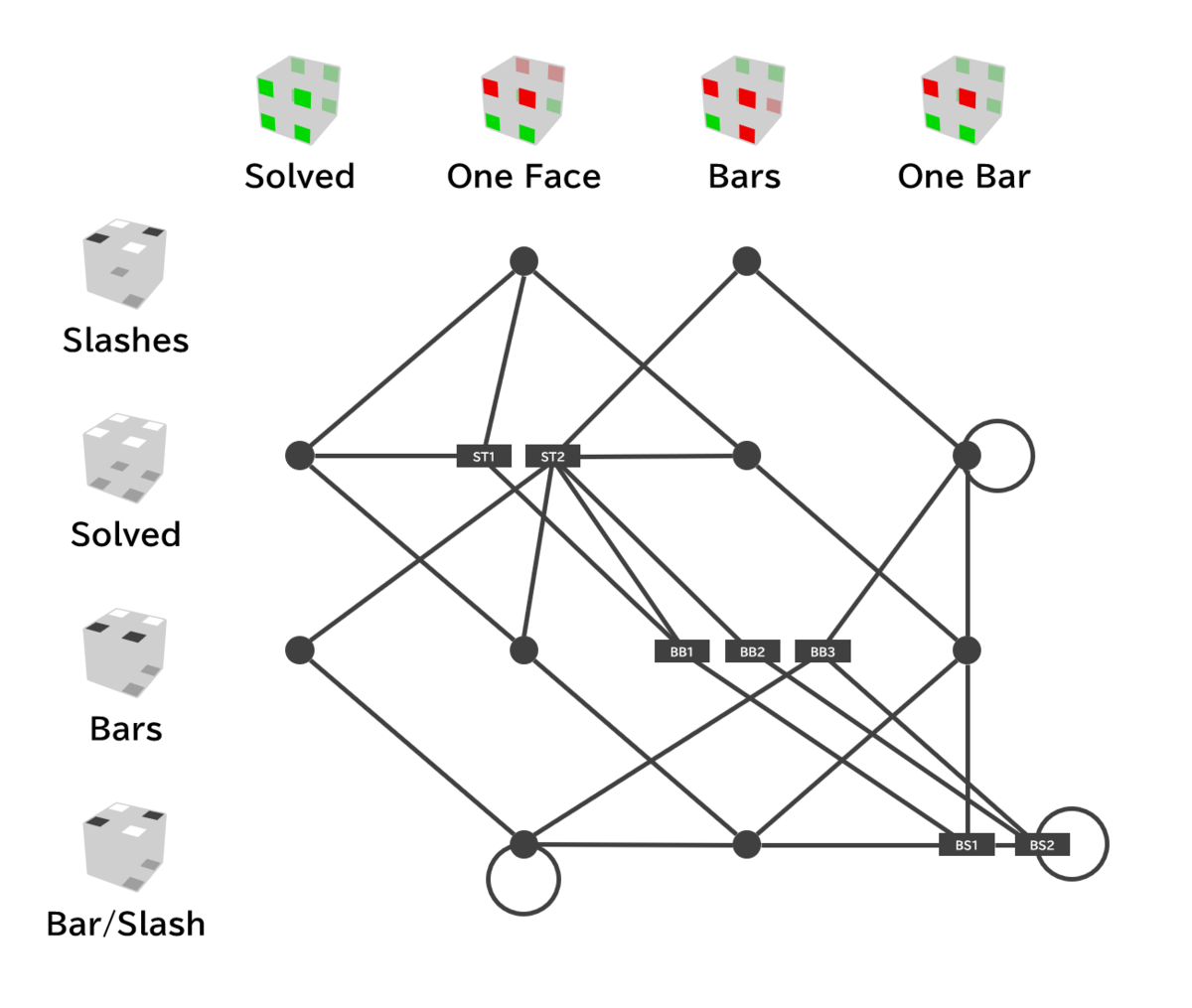
この図は、左上と右下を結んだ直線に対して微妙に線対称になっていないが、これはST1やST2など複数の状態があるものを横に並べているからで、これらを画面手前と奥の方向にでも並べれば、この図は完全に線対称になる。
NHKで目隠しでルービックキューブを揃えるという嘘が放送された(かもしれない)話
……をXで見かけた。 Xでいくら怒りをツイートしても、次にどこかの番組が「目隠しでルービックキューブ揃えられる人を紹介する企画とかどうかな」と思ったときに目に止まることはなく、同じ事が繰り返されるだろう。 ブログに書いておけば、目に止まる確率が多少は上がるだろう、ということでまとめておく。
次のような論点があって、私には嘘なのかどうかの判断が付きかねる。
- 「目隠しでルービックキューブを揃える」の一般的な定義は何か
- 番組と出演者はどのような定義だと思っているのか
- 出演者はその定義に反する揃え方をしたのか
どれも分からん。
なお、私は、以下のWCAの定めるレギュレーションに沿って、目隠しで揃えることはできる。 5分間くらい掛けて、2回に1回成功するくらいの確率。 公式の大会でも成功したので、そういう意味では揃えられるという証拠もある。
放送された番組
「有吉のお金発見 突撃!カネオくん」の2025年2月1日に放送された「クロスワードパズルのお金の秘密に迫る!」。 2月8日に再放送があるし、NHKオンデマンドで見られる。 該当の箇所は、オンデマンドでは再生時間の30分くらいから。
目隠しでルービックキューブを揃えるの定義は何か
ここが一番の問題だと思っている。
ある特定の状態のキューブについて解き方を覚えて、目隠しして揃えられるようになったとして、それで「目隠しでルービックキューブを揃えられる」と言えるかという話。 その揃えられるという人は、ある特定の状態についてしか目隠しで揃えられないという状況。
番組の後のほうで出てくる世界大会などは、WCA(The World Cube Association)が管轄(govern)している。 WCAの大会規則では、試技ごとにランダムにスクランブル(シャッフル)されたキューブが渡され、10分間とかの競技時間の間に、それを記憶して、目隠しして、揃える。 このスクランブルも、適当にガチャガチャ回すのではなく、コンピューターでランダムな状態を生成することになっている。 大会規則は以下のページに載っている。
WCA 大会規則 | World Cube Association
大会に出るガチな人達は、目隠しで揃えるというのは、このWCAのレギュレーション通りのことだと思っている。 一方で、詳しくない人にしてみれば、特定の状態だけでも目隠しで揃えられているのだから、揃えられるで良いんじゃない? と思うかもしれない。 ある状態について、競技のときの数分で覚えるか、何日も掛けて覚えるかの違いしか無いだろと言われれば、それもそう。 でも、ある状態についてだけなら、とても簡単ではある。 7-8手も回せばパッと見ぐちゃぐちゃになるし、7-8手くらいを覚えるのは簡単。
目隠しで揃える一般的な手法
超人的な技のように思えるかもしれないが、意外とできる。 私にもできた。 「1週間くらい掛けて何かを成し遂げたいな」と思っている人は、時間ができたときに挑戦してみると良い。 初めて揃えられたときは、なかなかの達成感があった。
手法は次の動画が詳しい。
要は、下図のように、どのピースをどこに移動すれば良いのかというのを記憶して、1個ずつ(上級者は2個ずつ)移動していく。

次の図のように、下面の十字を揃え、下2層を揃え、残り1面の上面の色を揃え、残り1面側面を揃える、スピード競技で一般的な解法(CFOP)とは全く異なる。

ここにも論点があり、「その目隠し嘘だろ。手順が違う」と指摘されていることがある。 目隠しでCFOPを使って揃えることができないのかどうか私には分からない。 世の中、映像記憶 というすごいスキルを持った人がいて、見たキューブの映像をそのまま頭に思い浮かべて解けるとしてもおかしくはない。 まあ、少なくとも、私の知る限り、大会で上位に入賞するような人達にそれをしている人がいないというのは事実である。
で、番組ではどうだったのか?
これが分からん。
まず、どちらの定義なのかは特に触れられていない。
揃える手順は、CFOPでも、1個ずつ移動していく感じでもなく見える。 2個ずつ移動する(3styleと言う)動きっぽくも見えるが、そもそも私ができないので分からん。
スクランブルは、良く見ると最初から揃っているピースがけっこうある。 ラッキーでそのくらい揃っていることもあるだろうし、例えば番組スタッフが雑に混ぜたらまあこのくらいになることはあるだろう。 「コンピューターでランダムにスクランブルしていないから嘘だ」というのは酷な気がする。
別でYouTubeにも動画を上げていて、これはさすがに最初から揃いすぎだろとは思う。 たぶん、CFOPの下2層を揃えるステップの最後あたりからやっているだけだよね。
番組に出てくれる人を探すには?
ガチで目隠しで揃えられる人は日本にもいっぱいいる。 トップ層だと、記憶する時間も含めて30秒も掛からないので、映えそう。
そういう人にコンタクトを取るには……どうしたら良いのだろう。
日本では、一般社団法人スピードキューブジャパン が大会を開いている *1 ので、連絡をすれば誰か紹介してくれるかもしれない。私が勝手に書いているだけなので、してくれないかもしれない。
*1:開いてないんだっけ? 委託(後援?)するから開く団体を募集しますみたいなお知らせを見た覚えがある。この辺良く分からん。
2x2x2キューブのPBLの下段が隣接交換で上段が完成状態はどう回すべきなのか
これ。

「こういう手順が良いよ」ではなく「どうしたら良いのだろうね」という記事である。
2x2x2キューブのOrtegaメソッドでは、D面を揃え、U面を揃え、その後、下段(D面)と上段(U面)の側面を同時に揃える。 この側面を同時に揃える手順がPBL(Permutation of Both Layers)である。
側面の状態として、完成、隣接交換、対角交換がある。



下段と上段の側面の状態の組み合わせごとに手順があり、私はこのシリーズの手順を使っている。
| 下段 | 上段 | 手順 | 補足 |
|---|---|---|---|
| 完成 | 隣接 | R' F R' F2 R U' R' F2 R2 | 上段の揃っているバーはB面 |
| 完成 | 対角 | R' F R' F2 R U' F R' F2 R U' R | |
| 隣接 | 隣接 | R2 U' R2' U2 F2 U' R2 | 上下段の揃っているバーはB面 |
| 対角 | 隣接 | R' F R' F2 R U' R | 上段の揃っているバーはF面 |
| 対角 | 対角 | R2' F2 R2 |
これらの手順は覚える事が少なくて良い。(下段/上段=)「完成/隣接」の R' F R' F2 R U' R' F2 R2 は、「対角/隣接」の R' F R' F2 R U' R に「対角/対角」の R2' F2 R2 を続け(て R をまとめ)た手順。「完成/対角」の R' F R' F2 R U' F R' F2 R U' R は、「対角/隣接」の R' F R' F2 R U' R を2回繰り返し(て R を消し)た手順。「対角/対角」の R2' F2 R2 は覚えるまでもないと考えると、実質的には「隣接/隣接」の R2 U' R2' U2 F2 U' R2 と「対角/隣接」の R' F R' F2 R U' R を覚えるだけで良い。
また、 R' F R' F2 R U' R は、慣れれば、 R2' F2 R2 のそれぞれの R2 の間にちょっと合いの手を入れるくらいの気持ちで回せるはずである。私はしょっちゅう引っ掛かるが……。
上記の表には、「隣接/完成」と「隣接/対角」、「対角/完成」が無いが、これらは上下をひっくり返せば表の状態のどれかになる。問題はどうやってひっくり返すかである。表を見ると分かるように、これらの手順では下段のバーをB面に置いて回すので、D面を揃えた段階でバーをB面にするか、もしくはD面を揃える前にバーがB面に来るような向きにしておくのが良いらしい。「隣接/対角」で下段のバーがB面にあるとき、 x2' で上下をひっくり返せば、バーが上段のF面になってそのまま手順を回せる。「対角/完成」は向きが関係無いので x2' で良い。x2' は回しやすい。「隣接/完成」は、 z2 でひっくり返すと、上段のバーがB面にある「完成/隣接」になって、手順が使える。が、しかし、 z2 って回しづらくない? キューブを落としそうになる。

要は、下段がバーをB面に置いた隣接交換、上段が完成状態で回せる手順が欲しい。自分で考えたのが次の手順。
x L' U L' U2 L F' R' F2 R2
x2 するとバーがF面に来る。その状態で完成させるためには奥のコーナーを入れ替えれば良くて、それは3x3x3のJaパームの R' U L' U2 R U' R' U2 L R 。2x2x2では L と R が等価なことを利用して調整という感じ。
x を右手で回し、その間に左手の親指をD面に持ってくると、以降は持ち替えずに回せる。 F' は右手親指で跳ね上げる。悪くはないけれど、急いでいると x L' とか F' のあたりが引っ掛かる。 z2 が辛いだけなら、 D2 x2' とか x2' U2 して「完成/隣接」の手順を回せば良いのではという気もする。新たに手順を覚えたり練習したりしなくて良いというメリットも大きい。
他の手順。
ちなみに、EG-1には、D面が不完全一面でU面が完全一面の状態(逆向きのT-perm)も含まれます。手順として何を使うかは完全に好みの問題ですが、筆者はバーをL面に置いて「R2 T-perm R2」というのを使っています。
パーフェクトEG-1ガイド①~Sune,Anti-Sune以外編~|いかのおすし
R2 とTパームの最初の R がキャンセルすることを考えると、B面にバーがある状態からなら、 D R' U R' U' R' F R2 U' R' U' R U R' F' R2 だろうか。
そう、EG-1の手順をまとめているページも、上段が完成状態のものはあまり載っていない。皆どうしているのだろう。
このサイトは、PBLのところに「完成/隣接」とは別に「隣接/完成」が載っていた。
D R2 U' R' U R' F2 R F' R' F2
どれが良いだろうか。
教えてもらった。
私はバーの位置によってそれぞれの手順を覚えており、B面バーなら F2 R U' R' F2 R2 U' R' F R' を使っています
— Shota (@MegaDBL) November 27, 2024
参考https://t.co/Vq9Z0L2Cm1 pic.twitter.com/xj1tuhRkFX