暫定: 相対スコア 37,484,834,108点、68位。
システムテスト: 1,508,927,060,379点、65位
ソースコード: https://github.com/kusano/ahc017
アルゴリズム
- 焼きなまし法
- 遷移は、道路を工事する日を変える
- 道路
mの工事する日を変えるとき、mの両端の交差点をuとvとして、uとvそれぞれからの各交差点の最短距離の和の工事日の変更による差分を、遷移を決定するときの差分とする- スコアの差分の真の値を求めるのが遅いため
- この差分を計算するときは、
uからの距離が300未満の交差点のみを対象とする
詳細
1回目の土日
何もせず。登録すらしていなかった。
月曜日、火曜日
登録して問題を見てみる。 どう見ても焼きなまし。 AtCoderのヒューリスティックコンテストは、単に焼きなましやビームサーチをするだけの問題は出ないイメージがある。 面白くないからね。 でも、この問題は焼きなましにしか見えないし、問題応じた工夫の余地があるようにも見えない。 この問題で焼きなましに頼らずに工事日を決めるのは無理だよね……? どういうこと?
ところで、この頂点数で全点対間最短距離を求めるのは無理では? ワーシャルフロイドは O(N3) だが……。 ローカルテスターを見たら、各頂点に対してダイクストラ法を使っていた。 ああ、辺数が O(N) だから、こっちのほうが速いのか。
水曜日
スコア計算を実装して、工事日を1, 2, 3, ..., K, 1, 2, ... と順番に割り振ってみる。
(絶対スコアで)47,705,877,230点。
焼きなましを実装。 イテレーションが100回くらいしか回らない。 なるほど、「素直な焼きなましでは全然速度が出ないでしょ? さあ、どうしますか?」という問題なのか。
39,292,621,530点。
孤立する交差点ができてる。 問題設定的に(たぶん)孤立する交差点は消せるようになっているので、孤立する交差点を消さないことには話にならないだろう。
木曜日
全点対間距離の計算は重すぎる。
1個の頂点と他の頂点の距離でもいいだろ。
少なくとも、孤立する交差点は検出できる。
どれか1個を選べと言われたら中央に近いものだよね。
読み捨てていた X と Y を活用。
スコアは×Nをして、元のスコアに合わせた。
桁くらいは合うはず。
焼きなましの遷移確率の計算では、大小関係だけではなく、差分にも意味がある。
イテレーションが数万回くらいは回るようになり、孤立した交差点が消えた。
776,408,368点。
これがスタートラインか。
金曜日
中央の交差点からの距離では、円周方向の道路を通らない。 パッと思いつく回避策は、1個ではなく、複数の交差点からの距離を見ること。 でもその分計算は重くなる。
ある道路を工事する日付を変えるとき、最も影響が大きいのは、その道路の両端の交差点である。 工事する道路から遠く離れた交差点同士の距離は、全く影響を受けないか、遠回りも容易だろう。 たぶん。
焼きなましの試行のたびにスコアの近似方法が変わっているわけで、この差分を足し合わせていくとスコアがマイナスになる。 こんなんで大丈夫かと思ったけど、真のスコアも下がっているの大丈夫っぽい。
684,397,753点
このアイデアは他でも使えそうだ。 スコアを近似するのではなく、差分を近似しても良いと。
この辺で、制限時間の6秒を10分にして動かしてみる。 これには2個の意味がある。
1個は、高速化に意味があるのかが分かること。 100倍高速化すればこのスコアが取れるということである。 だいぶスコアが小さくなるので、意味はありそう。
もう1個は、最適に近い解がどのような解なのかが分かること。 軽い計算でそのような解が作れるようになると嬉しい。 結果はこんな感じで、なんか工事する道路がパスのようになる。
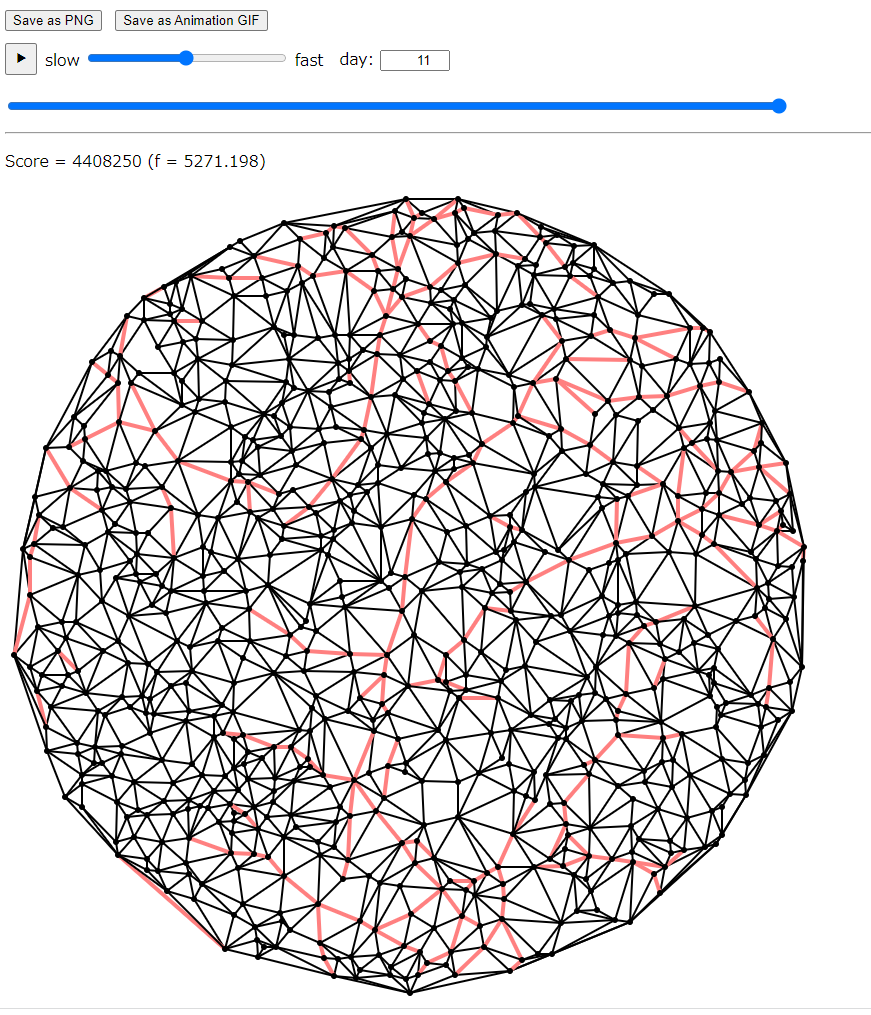
なぜ? 工事する道路はばらけていたほうが良いのでは? これが分からずに終わり。 もっとちゃんと考えれば良かった。
解説放送によると、ある道路が工事中のときそこは遠回りをするようになる。 その遠回りというのは、工事中の道路の直前で回避するのではなく、もっと大回りをする感じ。 なので、周囲の道路も工事して良いと。 なるほど。
各日に工事する道路の本数は多少偏る。
均等に割り振るのが最適なら K の制約は要らないわけで、偏るだろうなとは思っていた。
でも、 K まで使いきる感じでもないな。
良く分からん。
まずはスコア大きく悪化する孤立した交差点を消すことが重要。 孤立した交差点の有無でスコアが大きく変わるので、このときは細かなスコアはどうでも良い。 幅優先探索で数頂点が連結しているかどうかを調べるだけなら軽い。 数頂点が繋がっていれば、そこに繋がる道路も多いわけで、それらが同時に工事される確率は無視できるのでは? 先にこの軽い版で孤立した交差点を消してみるか → 意外と固まった数頂点の周囲の道路全部工事していることがある。 ボツ。
周囲のほうの道路とかどうでも良いよね。 重要なのは通る回数が多い中央部分。 焼きなましで中央のほうが選択される確率を上げたら良いのでは? → 別に良くなかった。 ボツ。
スコア計算のとき、全ての頂点との距離を調べる必要ある? 近い128頂点くらいで良くない? → 良かった。
598,947,065点
土曜日
dijkstra(d, p) を d 日目の頂点 p から各頂点への距離を返す関数、 R[m] を道路 m を何日目に工事するかの変数とし、 R[m] を d0 から d1 に変えるときのスコアの差分を今はこのように計算している。
long long diff = 0; R[m] = d0 diff -= sum(dijkstra(d0, U[m])); diff -= sum(dijkstra(d0, V[m])); diff -= sum(dijkstra(d1, U[m])); diff -= sum(dijkstra(d1, U[m])); R[m] = d1 diff += sum(dijkstra(d0, U[m])); diff += sum(dijkstra(d0, V[m])); diff += sum(dijkstra(d1, U[m])); diff += sum(dijkstra(d1, U[m]));
ダイクストラが8回でなかなか重い。 式変形をすると、これで計算できることが分かる。
long long diff = 0; R[m] = d0; DU = dijkstra(d0, U[m]); DV = dijkstra(d0, V[m]); for (int i=0; i<N; i++) diff -= max(0LL, abs(DU[i]-DV[i])-W[m]); R[m] = d1; DU = dijkstra(d1, U[m]); DV = dijkstra(d1, V[m]); for (int i=0; i<N; i++) diff += max(0LL, abs(DU[i]-DV[i])-W[m]);
さらに、 dijkstra(d0, U[m]) と dijkstra(d0, V[m]) はだいたい同じような更新順序になるので、 DU[p] か DV[p] のどちらかが更新されたら p に繋がっている距離を更新という感じでまとめられた。
また、 d0 から d1 に変えるコストを計算するときに、ついでに d0 から d2 や d0 から d3 も計算すると、 d0 の値が使い回せてお得。全ての日を候補にしたら(イテレーションが回らなくなるから?)返って悪くなったので、最大8日を候補にした。
適当。
593,323,301点
スコアがほとんど変わっていないのは、近い128頂点を見るというのを止めて、全ての頂点を見るようにしたから。 近い頂点というのは道路の状況によって変わるので、まとめられない。
ここで近いと言っているのは道路を辿って移動する距離。
直線距離で対象を決めれば、道路の状況が変わっても対象が変化しないか。
絞りすぎると上手くいかなかったので、直線距離が300未満の頂点を対象にした。
本当は N や M の値によって変えるべきかもしれない。
549,097,144点
日曜日
焼きなましでは、制限時間に達したときに温度が0になるようにしている。 最後の最後まで悪くなる遷移もする可能性がある。 これでスコアが悪化することを防ぐために、最後の状態ではなく、これまでの最高スコアのものを出力するようにしている。 普通はこれで良いと思うのだけど、遷移の度にスコアの計算方法が違うから、スコアの値がおかしくなっていて良くなさそう。 最後0.6秒くらいは温度を0(山登り)をするか。
549,594,670点
ちょっと悪化。 でも、このほうが良いと思うんだよな。 運が悪いだけでしょ、とそのままにした。 本当はローカルで1,000テストケースくらい回して決めたほうが良い。
あと、これまでのベストではなく、最終結果を出すようにしたほうが良いかも……と思ったが、これは結構悪化したので止めた。
ちょっとお出かけ。
終了30分前にくらいに帰宅して、そういえば時間制限を5.5秒にしていたけど、実際の実行時間が5.6秒くらいだったことに気が付いた。 もうちょっと攻めても大丈夫だろうと、時間制限を5.8秒に。
549,475,202点
やり残したこと
とにかくダイクストラ法が重い。 ダイクストラ法はフィボナッチヒープというのを使うとオーダーが改善するらしい。 理論的には速いというものではなく、ちゃんと速くなるらしい。
なんか難しそうで諦めた。 でも、コンテスト終了後に言及している人がいないので、わりと綺麗な平面グラフである今回の問題では役に立たないのかもしれない。 むしろ、ただのFIFOキューのほうが速いとか何とか。
ダイクストラよりSPFAの方が速かった。まぁ平面グラフなのでそんなもんなのかも。 https://t.co/pF1T0ABJbr #AHC017
— not@Optuna本2/21発売 (@not_522) February 5, 2023