19,937,073,060 点で暫定77位。
追記。
システムテストは、825,977,155,719点で74位。
問題概要
整数 M とエラー率 e が与えられる。
自分の作ったプログラムはそれに対して N を決めて、 N 頂点のグラフを M 個返す。
ジャッジは0以上 M 未満の整数 x を決めて、対応するグラフを選び、各辺を確率 e で反転させ、頂点をシャッフルして渡してくる。
それに対して整数 x を答える。
正解率が高いほど、 N が小さいほど高得点。
これが絶対スコア。
採点は相対スコア。
各ケースごとに、参加者中で最も高いスコアの何%のスコアを得られたかが相対スコアで、これが順位付けに使われる。
こんな採点方法もあるのか。
e が大きいと絶対スコアが何桁も下がるので、それの対策だろう。
しかし、普段のAHCだとスコアを徐々に上げていくのが楽しいが、相対スコアだと他の参加者が最高スコアを更新すると自分のスコアが下がるんだよな……。 賽の河原で積み上げた石を崩される感。
11月16日(水)
やる💪 #HTTF
— kusanoさん@がんばらない (@kusano_k) 2022年11月16日
HACK TO THE FUTURE 2023 予選(AtCoder Heuristic Contest 016) - AtCoderhttps://t.co/5zOdnSudrc pic.twitter.com/IPCWG5GyqB
11日(金)からコンテストは行われていたけど、ここから参加。 前の土日はSECCON予選に参加していたのでしょうがない。
とりあえず全部0を返すだけのコードを提出。
453,607点。
Gitのコミットメッセージにはスコアを入れている。
順位表に出てくる相対スコアは他の参加者の提出によって変わるので、絶対スコアのほうが良い……と思ったけど、絶対スコアは絶対スコアで e が大きいところのスコアが小さすぎて分かりづらい。
提出は30分間隔の制限があるし、ローカルテスターで動かしてスコアを集計するのも面倒。 ジャッジ側の実装は簡単なので、VC++でコンパイルしたときには50ケース実行してスコアを出力するようにした。
辺の本数にエンコードする。
0なら辺が0本、1なら1本、…。
簡単ですね。
問題ページのサンプルプログラムもこれ。
ただし、サンプルプログラムは N が固定のところ、 M 未満を表現できる最小の N を使うことにした。
8,040,225点。
辺の本数にエンコードすると、1本でも違ったらエラーになってしまう。
辺は最大4,950本もあり、 M は最大10なので、活用しないのはもったいない。
0なら0本、1なら10本、2なら20本、…とすれば多少のエラーには耐えられる。
単純に一番近いものを選べば良いかと思ったけど、これでは上手く行かない。
エラーが起こると、辺の本数は、正規分布っぽく、中央値に移動していく感じになる。
返ってきたグラフの変数が x 本のときは、 x 本になる確率が最も高いものを選べば良いはず。
数式一発で答えが出そうだけど、分からん。
無かった辺が増える本数をループで回して で解いた。
素直に掛け算したら浮動小数点数の精度が足りなくて無限大になる。
中身は全部掛け算なので、こういうのはlogを取って足し算をすれば良い。
158,501,069点。
間隔は、 w = (N*(N-1)/2-1)/(M-1) として、0本から M 本までを使うようにしている。
これ、たぶん、等間隔ではなく、中央辺りは見分けが難しいから広く取るとかしたほうが良いよね。
これもなんか数式一発で最適な方法が出てきそうだが……分からないので諦め。
統計検定2級を取ったけど、全て忘れていて何の役にも立たない。 ヒューリスティックコンテストで、「この改善は本当に有意な改善なのか?」とか「どのくらいのテストケース数で試せば良い?」とかも分かるだろうし、もう1回勉強し直したほうが良いのかもしれない。
頂点を3個のクラスタ(完全グラフ)に分けて、そのクラスタのサイズに情報を埋め込んでみる。
完全グラフなら辺が大量にあるので、エラーで多少辺が消えても、クラスタっぽいところを選べば元通りのはず。
2個のクラスタだと 種類の情報しか埋め込めなくて足りないが、3個だと [tex:O(N2)] なので充分。
クラスタのサイズはなるべく100/3に近くなるようにした。
386,149,705点。
11月17日(木)
全ての頂点をクラスタに含めようとするから3個必要になるのであって、クラスタに含めない孤立した点も許せば、クラスタ2個でいけるんじゃない?
369,856,736点
いけませんでした。 クラスタ3個に戻そう。 浮いている頂点か、たまたま辺が多めに消えただけの頂点かの判別が難しい。 「どのクラスタに属していますか?」のほうが簡単。
N=100 で固定していた。
M や e が小さいときは、100%正解するので、そんなに要らない。
M と e を10等分くらいに区切って、それぞれごとに最適な N を事前計算。
e が大きいときに N が小さくなるのが面白い。
どうせ当てずっぽう以上の正解率にならないなら、 N を小さくしたほうがスコアが上がるということか。
819,627,301点
ここからどうするか。
この問題は e や M の値によって解き方が全く変わると思う。
自分がどこが劣っているのかを知りたい。
最高スコアに近いスコアを取っているケースよりも、最高スコアから大きく劣っているケースを改善するほうが簡単なはずである。
相対スコアを利用して知ることができる。 特定のケース意外をわざとREにして、そのときの相対スコアと、AC数から期待されるスコアを比べれば良い。
full: AC=50 19,616,049,784 e<0.1: AC=13 5,364,873,351 / 5,100,172,943 = 105 % e>0.3: AC=12 658,952,483 / 4,707,851,948 = 14 % M<30: AC=11 3,892,215,217 / 4,315,530,952 = 90 % M>81: AC=10 4,278,657,239 / 3,923,209,956 = 110 %
e が大きいときが最悪。 e が大きいときがこれだけ低いのに、 e が小さいときが100%ちょっとということは、 e が小さいときもダメ。
M は、まあそんなに偏りは無いか。
まずは、方法は思いついていてやるだけだった e が小さいほうを何とかする。
グラフの同型判定は難しい問題である。 でも、6頂点でもグラフは156個もあって、今回の100未満の整数を表現するには充分。 6頂点くらいなら同型判定もできる。
グラフを送って素直に同型判定をするだけの処理を実装。
e=0.0 はこれで良い。
5頂点のグラフが34個、4頂点のグラフが11個なので、 M<=34 ならば e=0.1、 M<=11 ならば e=0.2 でもこれを使うようにした。
ちょっとくらい間違えても N が小さいというメリットが勝る……はず。
1,114,762,760点
クラスタ3個のサイズにエンコードするやつ、サイズが1刻みだけど、 M が小さかったら3刻みでも良いよね。
2刻みは間になったときにどちらだったのかが分からないのでNG。
1,296,211,660点
11月18日(金)
e が大きいところをどうするかな……。
16頂点の完全グラフを6個作って、そこに6頂点のグラフを埋め込んだらどうだろうか。
こういうイメージ。
16頂点の完全グラフには辺が120本もあるし、16頂点の完全グラフ2個の間には辺が256本も引ける。
これだけあれば e=0.4 程度のエラーへの耐性は充分だろう。
だめだった。 完全グラフの間に辺を引きすぎると、くっついてどこが完全グラフか分からなくってしまう。 64本程度でもエラー耐性としては充分かもしれないと思ったが、最大64本ところを0本や64本にするのと、最大256本のところに64本では見分ける難易度が違う。
パラメタを探索したら、 e が大きいときは諦めて N を小さくしていたけど、どうせ諦めるなら N=4 のほうが良い。
クラスタのサイズにエンコードするやつは N に下限がある。
M と e の組み合わせ全てに対して、どれが良いのかを調べるか。
このときについでに辺の本数にエンコードするやつも含めたら、 M が小さく e が大きいときに出てきた。
へー。

黄色がクラスタのサイズ、赤いところがグラフの同型判定、黄緑色が辺の個数、緑が N=4 で固定で0を返す。
ついでにクラスタのサイズにエンコードするときの、 N (上)とサイズの間隔(下)。
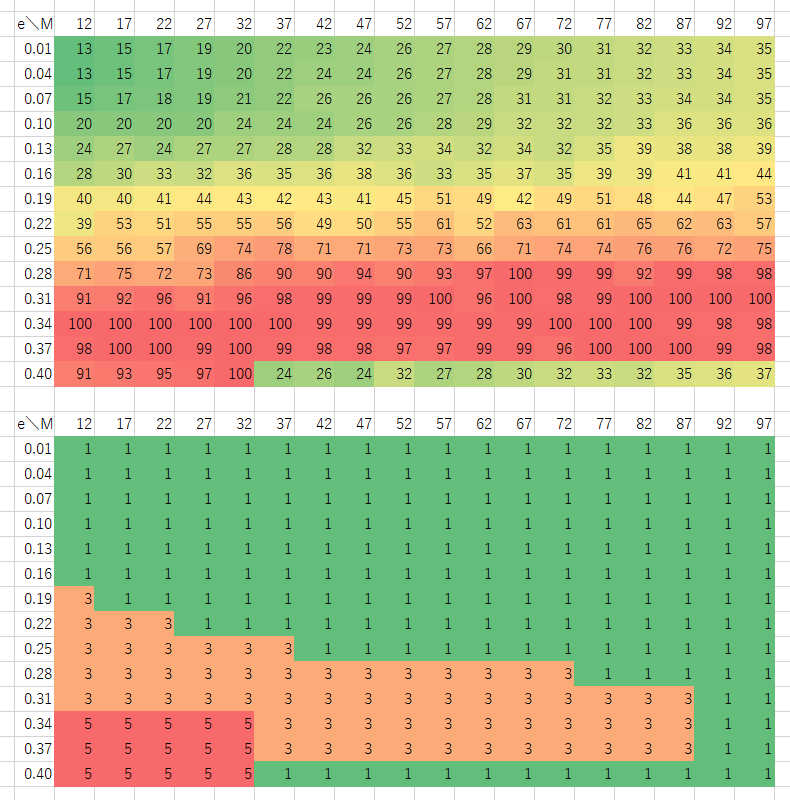
時間が掛かるので、こちらは間隔が粗め。 クラウドの活用を考えても良いかもしれない。 たぶん、手元のPCで1日掛かるくらいの計算なら、数百円&1時間くらいでできそう。
11月19日(土)
4個のクラスタにエンコードしたら良い感じになりませんか? → なりませんでした
16頂点の完全グラフを6個作って~というやつ、完全グラフ間の辺を引けるところには全部引いちゃって良いのでは? 今までは16個の頂点間に辺が多いかどうかを見ていたけど、他のどのグラフに辺が伸びているかどうかで区別ができるのでは? もしそれも同じなら区別する必要が無い。つまり、隣接行列で見たときに似ている行をクラスタとしてまとめれば良い。
クラスタの16頂点は完全グラフにしていたところ、逆に辺を全て無くしたらちょっと正解率が上がった。 ああ、自己辺は無いから、似ているところをまとめるときに、都合が良いのか。
この辺で、
# ## # ### # # ## # ### #
こういう隣接行列のグラフを
#### ########
#### ########
#### ########
#### ########
#### ############
#### ############
#### ############
#### ############
#### ####
#### ####
#### ####
#### ####
######## ####
######## ####
######## ####
######## ####
############ ####
############ ####
############ ####
############ ####
こうしていることになるのだと気が付いた。 ビジュアライザをちゃんと使っておけばもっと早く気が付いたかもしれない。 もったいない。
この辺でもう1回パラメタごとのスコアを調べてみる。
full: AC=50 20,588,242,805 e<0.1: AC=13 6,191,925,460 / 5,352,943,129 = 116 % e>0.3: AC=12 1,665,638,029 / 4,941,178,273 = 34 % e>0.35: AC= 7 172,974,952 / 2,882,353,992 = 6 %
e>0.35 も調べてみたけどボロボロだ。
今何とかしようとしている方法なら、エラーにも強いと思うんだよな。
11月20日(日)
最終日。
ということをしようとしている。 1番目が上手くいかない。
そもそも N=6 のグラフなんて(使っているのは)100個しかないのだから、100個それぞれに対して、↑の図示の下のほうの隣接行列を用意して、辺を入れ替えてどれだけそれに近づけるかを焼き鈍しすれば良いよね。
先にクラスタを作るより楽そう。
なんかフローとかを使って何とかならないかな~と考えているときに、 N=100 のグラフの同型判定そのものを解こうとしていることに気が付いた。
最終的に、 e が大きいところでは、4回実行してときどきこの手法のほうが良いと出てくるようにはなった。
が、まあ、たまたまだろうし、たまたまでなくても終了1時間前にこれをサブミットするのは怖い。
で、土日は結局何の成果も得られずに終わり。
グラフの同型判定の計算量は良く分かっていないけど、難しい問題ではあるので、同型判定で解こうとしてはいけないんですね~と思っていたけど、結局同型判定に戻ってきたので、ちゃんと考えるべきだった……。